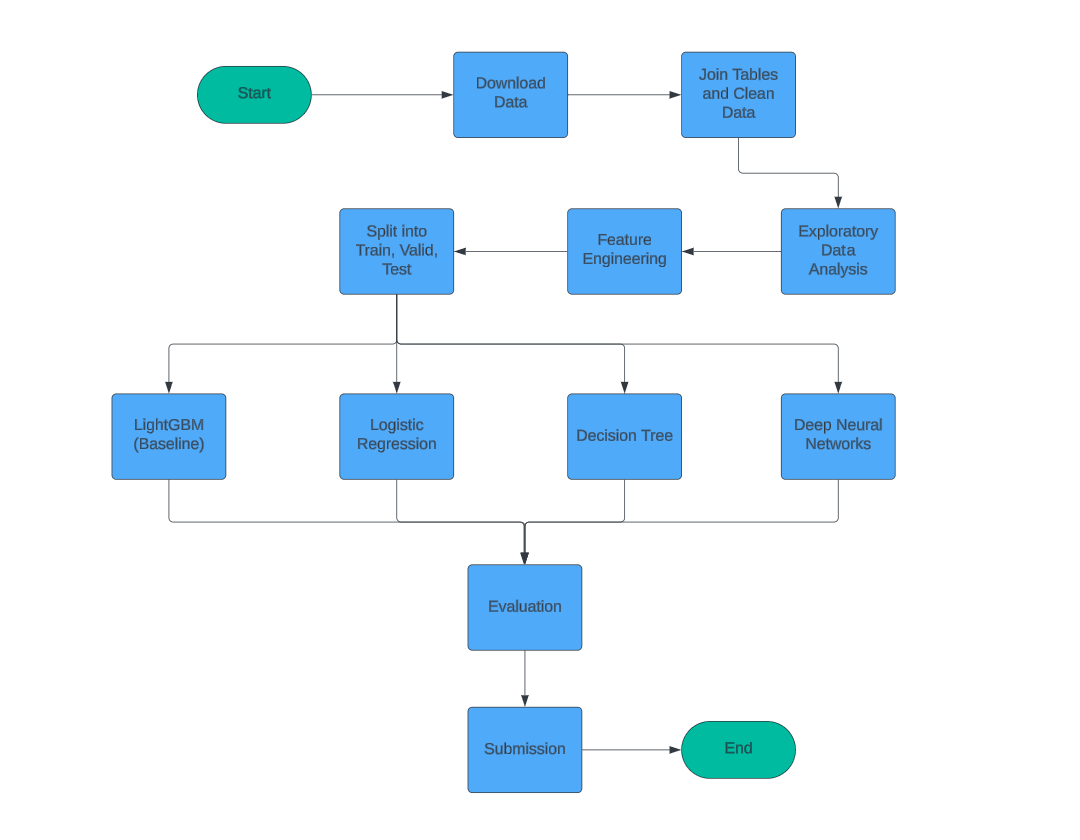
Overview
Kaggle competition hosted a consumer credit provider who focuses on responsible lending to people with little or no credit history. The aim of the competition was to create a credit risk scoring model which remains effective and stable over time. Data Science could help better predict loan repayment capabilities such that consumer lending can become more inclusive and acessible. If there are less unknowns, then lenders can reduce conservative naive approaches.
In this exercise, I explore traditional Machine Learning approaches and Deep Learning approaches. Deep Learning can provide new opportunities for credit modeling and has not been extensively applied in the real world much as of current. Some reasons being that they are newer methods and are considered "Black Box" models and lack explainability and transparency. However, proving the credibility of these models can pave the road for more adoption in the industry in the future when explainability methods improve.
View on GitHub